最近的文章列表
- 解决PHP中file_get_contents函数抓取https地址出错的两种方法
方法一:
在php中,抓取https的网站,提示如下的错误内容:
Warning: file_get_contents() [function.file-get-contents]: failed to open stream: Invalid argument in I:Webmyphpa.php on line 16
打开php.ini文件找到 ;extension=php_openssl.dll ,去掉双引号”;” ,重启web服务器即可。
apache服务器的话,可以同时启用mod_ssl模块测试。
- 2015/12/31 Comments:函数https抓取网页
- PHP curl库实现抓取网页来整站克隆功能(附代码)
有时候经常会用到一些在线手册,比如国内或国外的,有些是访问速度慢,有些是作者直接吧网站关闭了,有些是服务器总是宕机,所以还是全盘克隆到自己服务器比较爽。
库特点:
给定一初始连接,初始链接以下的层级所有文件会拷贝到本地。
多次克隆可以配置是否覆盖。
可以配置是否下载图片。
所有链接替换为相对链接,所以可以随便rewrite。
绝对不会出现文件覆盖等问题。
最NB的特点是,没有比这更NB的库了。- 2015/7/17 Comments:curl抓取网页
- 分享PHP抓取Google IP并自动修改hosts文件来实现翻墙
分享给大家找到的一个php版本的抓取google hosts的文件,试了下还可以用,ping了下ip,延迟也不是很高,网页打开测试了下速度也很快,大家有兴趣的话可以试试.
自动更新hosts文件, 不覆盖已存在的记录,方便使用,不用每次都 复制->打开hosts文件->粘贴。
php文件:
<?php
/**
* 免翻墙上google- 2015/7/16 Comments:Google抓取网页hosts翻墙
- 解决PHP Curl出现403错误的办法 curl_setopt
自己用的小PHP应用,使用curl抓网页下来处理,为了穿墙方便,使用Privoxy作为代理,便于选择哪些网站使用proxy、哪些不用。但今天却遇到了奇怪的问题,访问google baidu这些网站居然都返回403错误,而访问其他的一些网站没事,如果设置为不使用proxy则都能正常访问。
难道google baidu就不让用proxy连接么?显然不可能,所以打开curl的信息输出(curl_setopt($this->mSh, CURLOPT_VERBOSE, 1);)看看,得到以下结果:
- 2014/12/2 Comments:curl抓取网页
- HTML中rel的属性值canonical的介绍(辅助301永久重定向)
rel canonical 属性值 -- rel="canonical"属性让搜索引擎知道当前网站中的重复或相似网页中,哪一个页面才是站长想让其抓取与收录的
- canonical属性值通常在,rel属性中出现
- canonical从功能上来讲,可理解为301永久重定向的辅助功能
- canonical可以与相对链接或绝对链接一起使用,但是建议使用绝对链接
- 2014/9/19 Comments:301重定向SEO抓取网页
- php如何实现远程获取LOL数据示例代码(其实就是网页抓取内容)
最近完成了一个小功能,就是LOL数据获取,
比如:我给你一个号,你把这个号是否打过排位?战斗力是多少?胜率和所在的总场数数据获取过来
数据都在多玩的网站上可查,所以该做的功能就是远程抓取。
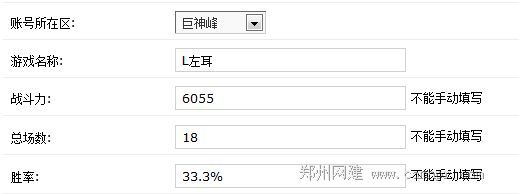
功能没啥亮点,就是简单的实现。
反正就是JS不能跨域,然后用PHP去跨域,用file_get_content好类
- 2014/9/15 Comments:lol抓取网页
- 【C#】抓取(获取)网页内容抓取图片的代码示例
1、抓取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
所需命名空间:System.Net、System.IO
核心代码:WebRequest request = WebRequest.Create("http://camnpr.com/");
WebResponse response = request.GetResponse();- 2014/7/26 Comments:抓取网页图片
- php curl_init函数用法
使用PHP的cURL库可以简单和有效地去抓网页。你只需要运行一个脚本,然后分析一下你所抓取的网 页,然后就可以以程序的方式得到你想要的数据了。无论是你想从从一个链接上取部分数据,或是取一个XML文件并把其导入数据库,那怕就是简单的获取网页内 容,cURL 是一个功能强大的PHP库。
PHP中的CURL函数库(Client URL Library Function)
curl_close — 关闭一个curl会话
curl_copy_handle — 拷贝一个curl连接资源的所有内容和参数
curl_errno — 返回一个包含当前会话错误信息的数字编号
curl_error — 返回一个包含当前会话错误信息的字符串
curl_exec — 执行一个curl会话- 2014/5/7 Comments:curl抓取网页教程
分门别类
 网站建设 (63)
网站建设 (63)- .Net知识问答 (137)
- 数据库 (75)
- 服务器 (92)
- 软件开发 (27)
- 性能优化_架构设计 (56)
- Javascript (441)
- Html_Css (75)
- Flash_Flex_AIR (37)
- PHP_Python (539)
- CMS_SNS (15)
- 编码百科 (8)
- 应用接口 (29)
- 搜索引擎 (6)
- 地图(Maps) (13)
- 游戏(Game) (29)
- 手机开发 (84)
- 软件问题 (169)
- SEO教程 (98)
- 杂谈 (288)
- 网站百科 (4)
关注本站
一条新消息
小编推荐
- 东东找到花花了
- 最新评论
- 最近访客