vs中查找的正则表达式规则 Visual Studio 2010中用正则表达式查找
我们要查找camnpr-数字-数字-数字.html (比如:camnpr-2-3-4.html)
于是,尝试使用下边的代码:
{"[^camnpr-(\d){1,}\-(\d){1,}\-(\d){1,}\.html$]"}^camnpr-(\d){1,}\-(\d){1,}\-(\d){1,}\.html$
结果都失败了,如图所示:
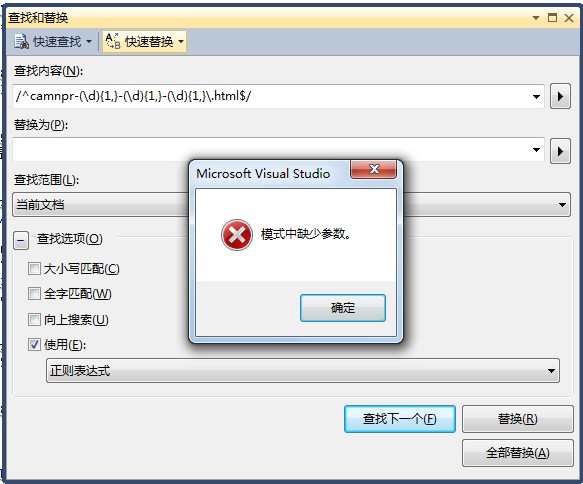
那么,正确的正则是这样的:东东找到花花了
camnpr-:d+-:d+-:d+.html
是不是很奇葩。微软自己搞的东东,唉。
下边来解释一下,查询的正则表达式书写含义:
经常会在Visual Studio中查找代码,采用正则表达式。但是经常查不到,很郁闷,一度以为自己正则表达式写错了。
这次,我决定去找一下到你VS2010尼玛用的是什么正则表达式引擎。
然后我发现了,果然跟通常的Perl引擎不一样。真不知道为啥VS自己搞了这一套。
http://msdn.microsoft.com/zh-cn/library/2k3te2cs.aspx
| 用途 | 新建 | 旧 | 新示例 |
|---|---|---|---|
| 匹配任何单个字符(分行符除外) | . | . | a.o 匹配“around”中的“aro”和“about”中的“abo”,但不匹配“across”中的“acro”。 |
| 匹配前面表达式的零个或更多匹配项(并匹配尽可能多的字符) | * | * | a*r 匹配 "rack" 中的 "r", "ark" 中的 "ar" 和 "aardvark" 中的 "aar" |
| 匹配任何字符零次或多次(通配符 *) | .* | .* | c.*e 匹配“racket”中的“cke”,“comment”中的“comme”,和“code”中的“code”。 |
| 匹配前面表达式的一个或更多匹配项(并匹配尽可能多的字符) | + | + | e.+e 与“feeder”中的“eede”而不是“ee”匹配。 |
| 匹配任一字符一次或多次(通配符 ?) | .+ | .+ | e.+e 匹配字符串"feeder"中的"eede",但是不匹配"ee" |
| 匹配前面表达式的零个或更多匹配项(并匹配尽可能少的字符) | *? | @ | e.*?e 与“feeder”中的“ee”而不是“eede”匹配。 |
| 匹配前面表达式的一个或更多匹配项(并匹配尽可能少的字符) | +? | # | “e.+?e”匹配“enterprise”中的“ente”和“erprise”,但不匹配完整的单词“enterprise”。 |
| 将匹配字符串锚定到行首或字符串首。 | ^ | ^ | ^car 仅当其在行首出现时才与“car”一次匹配。 |
| 将匹配字符串锚定到行尾 | \r?$ | $ | End\r?$ 只有出现在行尾时才与“end”匹配。 |
| 匹配一个集合中的任意单个字符 | [abc] | [abc] | “b[abc]”匹配“ba”、“bb”和“bc”。 |
| 匹配字符范围内的任意字符 | [a-f] | [x-y] |
be[n-t] 匹配 "between" 中的 "bet", "beneath" 中的 "ben", 和 "beside" 中的 "bes", 但不匹配 "below"。
|
| 获取包含在圆括号内的表达式并对其进行隐式编号 | () | () | “([a-z])X\1”与“aXa”和“bXb”匹配,但与“aXb”不匹配。".“\1”是指第一个表达式组“[a-z]”。 |
| 匹配无效 | (?!abc) | ~(abc) | “real (?!ity)”匹配“realty”和“really”中的“real”,但不匹配“reality”中的“real”。它还在“realityreal”中找到第二个“real”(但不是第一个“real”)。 |
| 匹配不在给定字符集中的任意字符 | [^abc] | [^abc] | “be[^n-t]”匹配“before”中的“bef”、“behind”中的“beh”和“below”中的“bel”,但是不匹配“beneath”。 |
| 匹配符号之前或之后的那个表达式。 | | | | | (sponge|mud) bath 匹配“sponge bath”和“mud bath”。 |
| 对反斜杠之后的字符进行转义 | \ | \ | ^ \ 匹配 ^ 字符。 |
| 指定前一个字符或组出现的次数 | {x},其中 x 是指出现的次数 | \x,其中 x 是指出现的次数 | x(ab){2}x 匹配“xababx”,x(ab){2,3}x 匹配“xababx”和“xabababx”而非“xababababx”。 |
| 匹配 Unicode 字符类中的文本,文本中的“X”为 Unicode 数字。 有关 Unicode 字符的更多信息,请参见 | \p{X} | :X | “\p{lu}”与“Thomas Doe”中的“T”和“D”匹配。 |
| 匹配字边界 | “\b”(在字符类 \b 之外指定字边界,并在字符类指定 Backspace)。 | “<”和“>”指定单词的开头和结尾 | “\bin”与“inside”中的“in”匹配,但与“pinto”不匹配。 |
| 匹配换行符(即,回车后跟一个新行)。 | \r?\n | \n | “End\r?\nBegin”仅当“End”是一行中的最后一个字符串和“Begin”是下一行中的第一个字符串时匹配单词“End”和“Begin”。 |
| 匹配任何字母数字字符 | \w | :a | “a\wd”与“add”和“a1d”匹配,但不匹配“a d”。 |
| 匹配任何空白字符。 | (?([^\r\n])\s) | :b | “Public\sInterface”匹配短语“Public Interface”。 |
| 匹配任何数字字符 | \d | :d | “\d”与和“3456”中的“3”、“23”中的“2”和“1”中的“1”匹配。 |
| 匹配 Unicode 字符 | \uXXXX,其中 XXXX 表示 Unicode 字符值。 | \uXXXX,其中 XXXX 表示 Unicode 字符值 | \u0065 匹配字符“e”。 |
| 匹配标识符 | \b(_\w+|[\w-[0-9_]]\w*)\b | :i | 与“type1”匹配,而不是与“&type1”或“#define”。 |
| 匹配引号中的字符串 | ((\".+?\")|('.+?')) | :q | 匹配单引号或双引号中的任意字符串。 |
| 匹配十六进制数 | \b0[xX]([0-9a-fA-F])\b | :h | 匹配“0xc67f”,不匹配“0xc67fc67f”。 |
| 匹配整数和小数 | \b[0-9]*\.*[0-9]+\b | :n | 匹配“1.333”。 |
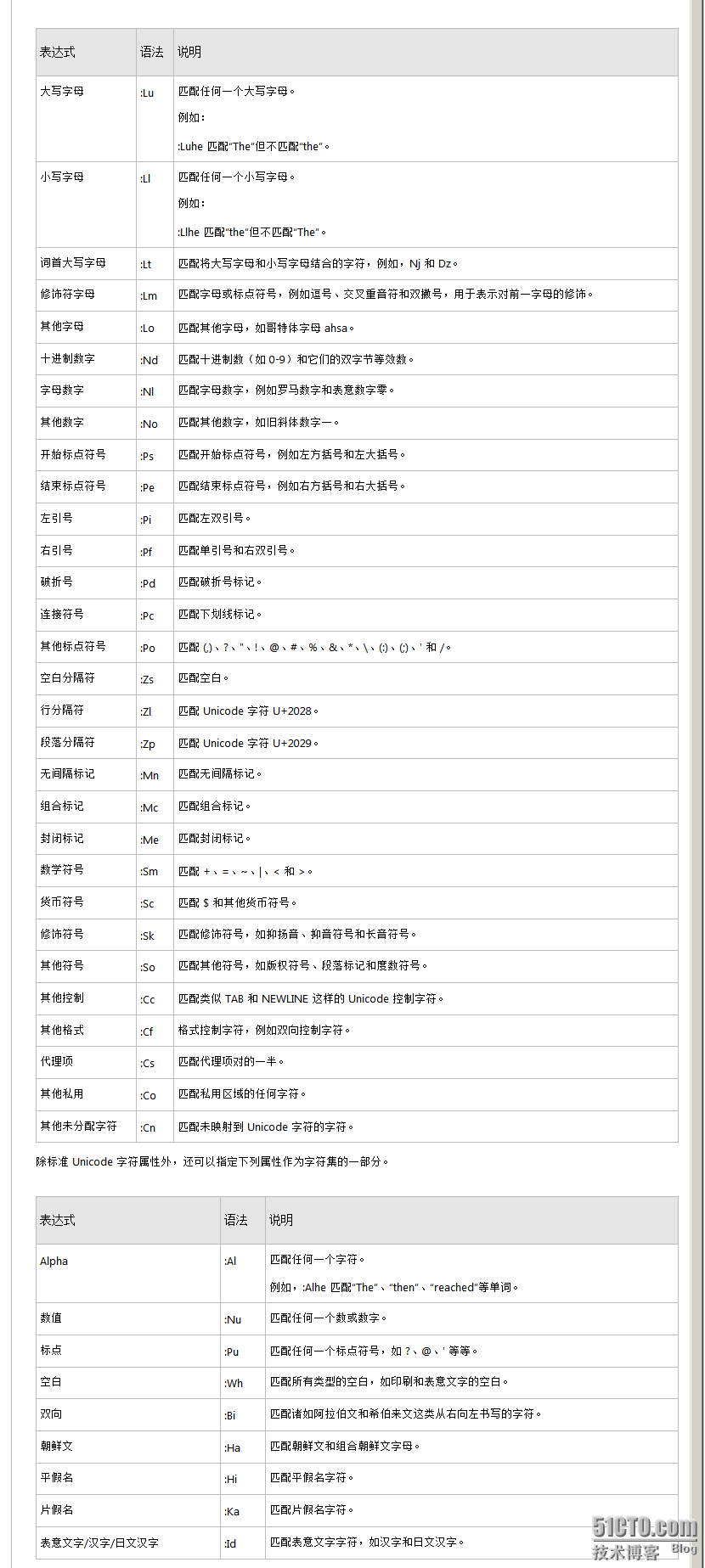
vs查询时需要的正则对照表:
本文链接:http://camnpr.com/archives/Visual-Studio-using-regular-expression-search.html
相关文章
- 前端必备的压缩工具 详述r.js的使用方法(2013-8-9 16:56:28)
- Vs2010中空格显示成了绿色的点 如果显示行号(2013-6-28 13:30:26)
- 推荐几个Web前端开发者/SEOer必用的Chrome浏览器扩展(2013-5-8 16:53:42)
- 收集23个web免费的图表、流程图工具(2013-4-7 10:48:29)
- 细说Drupal,Joomla,Wordpress的区别(2013-3-29 14:17:29)
- Source Insight 程序员的利器 最好用的语言编辑器(2012-4-25 15:55:15)
- [软件] 远程桌面连接管理软件RDO(Remote Desktop Organizer)(2012-4-25 13:44:38)
- 在线应用工具(2012-3-29 16:28:10)
- Axure RP 产品原型设计 网站构架图 示意图 流程图 交互设计 自动输出网站原型 自动输出wo(2011-12-30 15:0:21)
- 4个Web图片在线压缩优化工具(2011-11-12 9:32:49)