关系型数据库访问性能优化法则之程序员篇
声明:本文不是面向DBA,因为它是:DBA是数据库管理员,英文是Database Administrator。
DBA的一些职责: 安装和升级数据库服务器(如Oracle、Microsoft SQL server) ,以及应用程序工具。 数据库设计系统存储方案,并制定未来的存储需求计划。
一旦开发人员设计了一个应用,就需要DBA来创建数据库存储结构(tablespaces)。 一旦开发人 员设计了一个应用,就需要DBA来创建数据库对象(tables,views,indexes)。
根据开发人员的反馈信息,必要的时候,修改数据库的结构。 登记数据库的用户,维护数据库的安 全性。
保证数据库的使用符合知识产权相关法规。 控制和监控用户对数据库的存取访问。 监控和优化数据库的性能。
制定数据库备份计划,灾难出现时对数据库信息进行恢复 维护适当介质上的存档或者备份数据 备份和恢复数据库 联系数据库系统的生产厂商,跟踪技术信息。
这个优化法则归纳为5个层次:
1、 减少数据访问(减少磁盘 访问)
2、 返回更少数据(减少网络 传输或磁盘访问)
3、 减少交互次数(减少网络 传输)
4、 减少服务器CPU开销(减少CPU及内存开销)
5、 利用更多资源(增加资源 )
由于每一层优化法则都是解决其对应硬件的性能问题,所以带来的性能提升比例也不一样。传统数据库系统设计是也是尽可能对低速设 备提供优化方法,因此针对低速设备问题的可优化手段也更多,优化成本也更低。我们任何一个SQL的性能优化都应该按这个规则由上到下来诊断问题并提出解决方案,而不应该首先想到的是增加资源解决问题。
以下是每个优化法则层级对应优化效果及成本经验参考:
| 优化法则 | 性能提升效果 | 优化成本 |
| 减少数据访问 | 1~1000 | 低 |
| 返回更少数据 | 1~100 | 低 |
| 减少交互次数 | 1~20 | 低 |
| 减少服务器CPU开销 | 1~5 | 低 |
| 利用更多资源 | @~10 | 高 |
1、减少数据访问
1.1、创建并使用正确的 索引
数据库索引的原理非常简单,但在复杂的表中真正能正确使用索引的人很少,即使是专业的DBA也不一定能完全做到最优。
索引会大大增加表记录的DML (INSERT,UPDATE,DELETE)开销,正确的索引可以让性能提升100,1000倍以上,不合理的索引也可能会让性能下降100倍,因此在一个表中创建什么样的索引需要平衡各种业务需求。
索引常见问题:
索引有哪些种类?
常见的索引有B-TREE索引、位图索引、全文索引,位图索引一般用于数据仓库应用,全文索引由于使用较少,这里不深入介绍。B-TREE索引包括很多扩展类型,如组合索引、反向索引、函数索引等等,以下是 B-TREE索引的简单介绍:
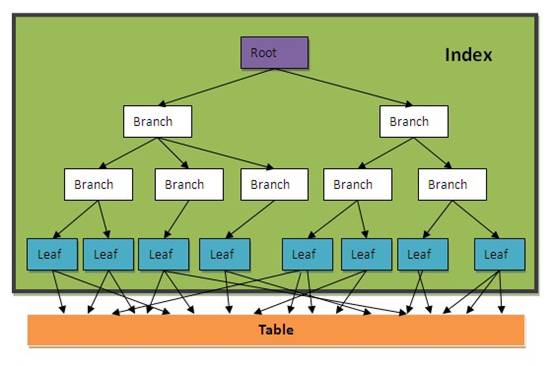
B-TREE索引也称为平衡树索引(Balance Tree),它是一种按字段排好序的树形目录结构, 主要用于提升查询性能和唯一约束支持。B-TREE索引的内容包括根节点、分支节点、叶子节点。
叶子节点内容:索引字段内容+表记录ROWID
根节点,分支节点内容:当一个数据块中不能放下所有索引字段数据时 ,就会形成树形的根节点或分支节点,根节点与分支节点保存了索引树的顺序及各层级间的引用关系。
一个普通的BTREE索引结构示意图如下所示:
如果我们把一个表的内容认为是一本字典,那索引就相当于字典的目录,如下图 所示:

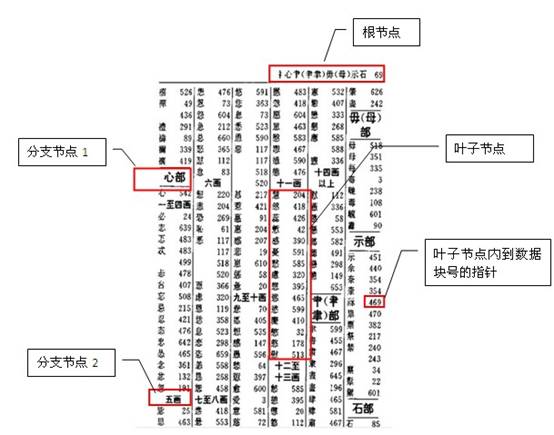
图中是一个字典按部首+笔划数的目录,相当于给字典建了一个按部首+笔划的组合索引。
一个表中可以建多个索引,就如一本字典可以建多个目录一样(按拼音、笔划、 部首等等)。
一个索引也可以由多个字段组成,称为组合索引,如上图就是一个按部首 +笔划的组合目录。
SQL什么条件会使用索引?
当字段上建有索引时,通常以下情况会使用索引:
INDEX_COLUMN = ?
INDEX_COLUMN > ?
INDEX_COLUMN >= ?
INDEX_COLUMN < ?
INDEX_COLUMN <= ?
INDEX_COLUMN between ? and ?
INDEX_COLUMN in (?,?,...,?)
INDEX_COLUMN like ?||’%’(后导模糊 查询)
T1. INDEX_COLUMN=T2. COLUMN1(两个 表通过索引字段关联)
SQL什么条件不会使用索引?
| 查询条件 | 不能使用索引原因 |
| INDEX_COLUMN <> ? INDEX_COLUMN not in (?,?,...,?) | 不等于操作不能使用索引 |
| function(INDEX_COLUMN) = ? INDEX_COLUMN + 1 = ? INDEX_COLUMN || ’a’ = ? | 经过普通运算或函数运算后的索引字段不能使用索引 |
| INDEX_COLUMN like ’%’||? INDEX_COLUMN like ’%’||?||’%’ | 含前导模糊查询的Like语法不能使用索引 |
| INDEX_COLUMN is null | B-TREE索引里不保存字段为NULL值记录,因此IS NULL不能使 用索引 |
| NUMBER_INDEX_COLUMN=’12345’ CHAR_INDEX_COLUMN=12345 | Oracle在做数值比较时需要将两边的数据转换成同一种数据类型,如果两边数据类型不同时会对字段值隐式转换,相当于加了一层函数处理,所以不能使用 索引。 |
| a.INDEX_COLUMN=a.COLUMN_1 | 给索引查询的值应是已知数据,不能是未知字段值。 |
| 注: 经过函数运算字段的字段要使用可以使用函数索引,这种需求建议与DBA沟通。 有时候我们会使用多个字段的组合索引,如果查询条件中第一个字段不能使用索引,那整个查询也不能使用索引 如:我们company表建了一个id+name的组合索引,以下SQL是不能使用索引的 Select * from company where name=? Oracle9i后引入了一种 index skip scan的索引方式来解决类似的问 题,但是通过index skip scan提高性能的条 件比较特殊,使用不好反而性能会更差。 | |
我们一般在什么字段上建索引?
这是一个非常复杂的话题,需要对业务及数据充分分析后再能得出结果。主键及外键通常都要有索引,其它需要建索引的字段应 满足以下条件:
1、字段出现在查询条件中,并且查询条件可以使用索引;
2、语句执行频率高,一天会有几千次以上;
3、通过字段条件可筛选的记录集很小,那数据筛选比例是多少才适合?
这个没有固定值,需要根据表数据量来评估,以下是经验公式,可用于快速评估 :
小表(记录数小于10000行的表) :筛选比例<10% ;
大表:(筛选返回记录数)<(表总记录数*单条记录长度)/10000/16
单条记录长度≈字段平均内容长度之和 +字段数*2
以下是一些字段是否需要建B-TREE索引的经验分类:
| 字段类型 | 常见字段名 | |
| 需要建索引的字段 | 主键 | ID,PK |
| 外键 | PRODUCT_ID,COMPANY_ID,MEMBER_ID,ORDER_ID,TRADE_ID,PAY_ID | |
| 有对像或身份标识意义字段 | HASH_CODE,USERNAME,IDCARD_NO,EMAIL,TEL_NO,IM_NO | |
| 索引慎用字段,需要进行数据分布及使用场景详细评估 | 日期 | GMT_CREATE,GMT_MODIFIED |
| 年月 | YEAR,MONTH | |
| 状态标志 | PRODUCT_STATUS,ORDER_STATUS,IS_DELETE,VIP_FLAG | |
| 类型 | ORDER_TYPE,IMAGE_TYPE,GENDER,CURRENCY_TYPE | |
| 区域 | COUNTRY,PROVINCE,CITY | |
| 操作人员 | CREATOR,AUDITOR | |
| 数值 | LEVEL,AMOUNT,SCORE | |
| 长字符 | ADDRESS,COMPANY_NAME,SUMMARY,SUBJECT | |
| 不适合建索引的字段 | 描述备注 | DESCRIPTION,REMARK,MEMO,DETAIL |
| 大字段 | FILE_CONTENT,EMAIL_CONTENT |
如何知道SQL是否使用了正确的索引?
简单SQL可以根据索引使用语法规则判断,复杂的SQL不好办,判断SQL的响应时间是一种策 略,但是这会受到数据量、主机负载及缓存等因素的影响,有时数据全在缓存里,可能全表访问的时间比索引访问时间还少。要准确知道索引是否正确使用,需要到数据库中查看 SQL真实的执行计划,这个话题比较复杂,详 见SQL执行计划专题介绍。
索引对DML(INSERT,UPDATE,DELETE)附加的开销有多少?
这个没有固定的比例,与每个表记录的大小及索引字段大小密切相关,以下是一个普通表测试数据,仅供参考:
索引对于Insert性能降低56%
索引对于Update性能降低47%
索引对于Delete性能降低29%
因此对于写IO压力比较大的系统,表的索引需要仔细评估必要性,另外索引也会占用一定的存储空间。
1.2、只通过索引访问数据
有些时候,我们只是访问表中的几个字段,并且字段内容较少,我们可以为这几个字段单独建立一个组合索引,这样就可以直接只通过 访问索引就能得到数据,一般索引占用的磁盘空间比表小很多,所以这种方式可以大大减少磁盘IO开销。
如:select id,name from company where type=’2’;
如果这个SQL经常使用,我们可以在type,id,name上创建组合索引
create index my_comb_index on company(type,id,name);
有了这个组合索引后,SQL就可以直接通过my_comb_index索引返回数据,不需要访问company表。
还是拿字典举例:有一个需求,需要查询一本汉语字典中所有汉字的个数,如果我们的字典没有目录索引,那我们只能从字典内容里一 个一个字计数,最后返回结果。如果我们有一个拼音目录,那就可以只访问拼音目录的汉字进行计数。如果一本字典有1000页,拼音目录有20页,那我们的数据访问成本相当于全表访问的50分之一。
切记,性能优化是无止境的,当性能可以满足需求时即可,不要过度优化。在实际数据库中我们不可能把每个SQL请求的字段都建在索引里,所以这种只通过索引访问数据的方法一般只用于核心应用,也就是那种对核心表访问量最高且查询字段数据量很少的查询。
SQL执行计划是关系型数据库最核心的技术之 一,它表示SQL执行时的数据访问算法。由于 业务需求越来越复杂,表数据量也越来越大,程序员越来越懒惰,SQL也需要支持非常复杂的业务逻辑,但SQL的性能还需要提高,因此,优秀的关系型数据库除了需要支持复杂的SQL语法及更多函数外,还需要有一套优秀的算法库来提高SQL性能。
目前ORACLE有SQL执行计划的算法约 300种,而且一直在增加,所以SQL执行计划是一个非常复杂的课题,一个普通DBA能掌握50种就很不错了,就算是资深DBA也不可能把每个执行计划的算法描述清楚。虽然有这么多种算法,但并不表示我们无法优化执行计划,因为 我们常用的SQL执行计划算法也就十几个,如 果一个程序员能把这十几个算法搞清楚,那就掌握了80%的SQL执行计划调优知识。
由于篇幅的原因,SQL执行计划需要专题介绍,在这里就不多说了。
2、返回更少的数据
2.1、数据分页处理
一般数据分页方式有:
2.1.1、客户端(应用程序或浏览器)分页
将数据从应用服务器全部下载到本地应用程序或浏览器,在应用程序或浏览器内部通过本地代码进行分页处理
优点:编码简单,减少客户端与应用服务器网络交互次数
缺点:首次交互时间长,占用客户端内存
适应场景:客户端与应用服务器网络延时较大,但要求后续操作流畅,如手机GPRS,超远程访问(跨国)等等。
2.1.2、应用服务器分页
将数据从数据库服务器全部下载到应用服务器,在应用服务器内部再进行数据筛选。以下是一个应用服务器端Java程序分页的示例:
List list=executeQuery(“select * from employee order by id”);
Int count= list.size();
List subList= list.subList(10, 20);
优点:编码简单,只需要一次SQL交互,总数据与分页数据差不多时性能较好。
缺点:总数据量较多时性能较差。
适应场景:数据库系统不支持分页处理,数据量较小并且可控。
2.1.3、数据库SQL分页
采用数据库SQL分页需要两次SQL完成
一个SQL计算总数量
一个SQL返回分页后的数据
优点:性能好
缺点:编码复杂,各种数据库语法不同,需要两次SQL交互。
oracle数据库一般采用rownum来进 行分页,常用分页语法有如下两种:
直接通过rownum分页:
select * from (
select a.*,rownum rn from
(select * from product a where company_id=? order by status) a
where rownum<=20)
where rn>10;
数据访问开销=索引IO+索引全部记录结果对 应的表数据IO
采用rowid分页语法
优化原理是通过纯索引找出分页记录的ROWID,再通过ROWID回表返回数据,要求内层查询和排序字段全在索引里。
create index myindex on product (company_id,status);
select b.* from (
select * from (
select a.*,rownum rn from
& nbsp; (select rowid rid,status from product a where company_id=? order by status) a
where rownum<=20)
where rn>10) a, product b
where a.rid=b.rowid;
数据访问开销=索引IO+索引分页结果对应的 表数据IO
实例:
一个公司产品有1000条记录,要分页取其中20个产品,假设访问公司索引需要50个IO,2条记录需要1个表数据IO。
那么按第一种ROWNUM分页写法,需要550(50+1000/2)个IO,按第二种 ROWID分页写法,只需要60个IO(50+20/2);
2.2、只返回需要的字段
通过去除不必要的返回字段可以提高性能,例:
调整前:select * from product where company_id=?;
调整后:select id,name from product where company_id=?;
优点:
1、减少数据在网络上传输开销
2、减少服务器数据处理开销
3、减少客户端内存占用
4、字段变更时提前发现问题,减少程 序BUG
5、如果访问的所有字段刚好在一个索 引里面,则可以使用纯索引访问提高性能。
缺点:增加编码工作量
由于会增加一些编码工作量,所以一般需求通过开发规范来要求程序员这么做,否则等项目上线后再整改工作量更大。
如果你的查询表中有大字段或内容较多的字段,如备注信息、文件内容等等,那在查询表时一定要注意这方面的问题,否则可能 会带来严重的性能问题。如果表经常要查询并且请求大内容字段的概率很低,我们可以采用分表处理,将一个大表分拆成两个一对一的关系表,将不常用的大内容字段放在一张单 独的表中。如一张存储上传文件的表:
T_FILE(ID,FILE_NAME,FILE_SIZE,FILE_TYPE,FILE_CONTENT)
我们可以分拆成两张一对一的关系表:
T_FILE(ID,FILE_NAME,FILE_SIZE,FILE_TYPE)
T_FILECONTENT(ID, FILE_CONTENT)
通过这种分拆,可以大大提少T_FILE表的单条记录及总大小,这样在查询T_FILE时性能会更好,当需要查询FILE_CONTENT字段内容时再访问T_FILECONTENT表。
标签:SQL Server
原创文章如转载,请注明:转载自郑州网建-前端开发 http://camnpr.com/本文链接:http://camnpr.com/database/114.html
相关文章
- sql查找某个月份在开始时间和结束时间之间的记录(2010-11-24 11:50:46)
- SQL SERVER 与ACCESS、EXCEL的数据转换(2010-10-18 11:6:0)
- 【SQL Server】Sql字符串ID转换成名字(2010-9-30 16:34:22)
- 【SQL Server】SQL日期格式化函数FormatDatetime(2010-9-30 16:0:35)
- 【SQL Server】Sql实现的字符串分割自定义函数:Split(2010-9-30 15:30:56)
- 【SQL Server】清除HTML的SQL用户定义函数--不使用正则表达式(2010-9-30 15:27:27)
- 【SQL Server】在SQL中实现分割字符串功能(类似Split)(2010-9-30 15:23:48)
- 【服务器】两个服务器上的两个数据库表进行关联查询(2010-8-25 18:5:12)
- 【MYSQL】.net链接mysql数据库,操作增删改查(2010-8-25 18:3:16)
- 【SQL】sql 语句处理 日期处理(2010-8-25 18:1:33)