关系型数据库访问性能优化法则之程序员篇2
3、减少交互次数
3.1、batch DML
数据库访问框架一般都提供了批量提交的接口,jdbc支持batch的提交处理方法,当你一次性要往一个表中插入1000万条数据时,如果采用普通的executeUpdate处理,那么和服务器交互次数为1000万次,按每秒钟可以向数据库服务器提交10000次估算,要完成所有工作需要1000秒。如果采用批量提交模式,1000条提交一次,那么和服务器交互次数为1万次,交互次数大大减少。采用batch操作一般不会减少很多数据库服务器的物理IO,但是会大大减少客户端与服务端的交互次数,从而减少了多次发起的网络延时开销,同时也会降低数据库 的CPU开销。
假设要向一个普通表插入1000万数据,每条记录大小为1K字节,表上没有任何索引,客户端与数据库服务器网络是100Mbps,以下是根据现在一般计算机能力估算的各种batch大小性能对比值:
| 单位:ms | No batch | Batch=10 | Batch=100 | Batch=1000 | Batch=10000 |
| 服务器事务处理时间 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| 服务器IO处理时间 | 0.02 | 0.2 | 2 | 20 | 200 |
| 网络交互发起时间 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| 网络数据传输时间 | 0.01 | 0.1 | 1 | 10 | 100 |
| 小计 | 0.23 | 0.5 | 3.2 | 30.2 | 300.2 |
| 平均每条记录处理时间 | 0.23 | 0.05 | 0.032 | 0.0302 | 0.03002 |
从上可以看出,Insert操作加大Batch 可以对性能提高近8倍性能,一般根据主键的 Update或Delete操作也可能提高2-3倍性能,但不如Insert明显,因为Update及Delete操作可能有比较大的开销在物理IO访问。以上仅是理论计算值,实际情况需要根据具体环境测量。
很多时候我们需要按一些ID查询数据库记录,我们可以采用一个ID一个请求发给数据库,如下所示:
for :var in ids[] do begin
select * from mytable where id=:var;
end;
我们也可以做一个小的优化, 如下所示 ,用ID INLIST的这种方式写SQL:
select * from mytable where id in(:id1,id2,...,idn);
通过这样处理可以大大减少SQL请求的数量,从而提高性能。那如果有10000个ID,那是不是 全部放在一条SQL里处理呢?答案肯定是否定 的。首先大部份数据库都会有SQL长度和 IN里个数的限制,如ORACLE的IN里就不允许超过1000个值 。
另外当前数据库一般都是采用基于成本的优化规则,当IN数量达到一定值时有可能改变SQL执行计划,从索引访问变成全表访问,这将使性能急剧变化。随着SQL中IN的里面的值个数增加,SQL的执行计划会更复杂,占用的内存将会变大,这将会增加服务器CPU及内存成本。
评估在IN里面一次放多少个值还需要考虑应用服务器本地内存的开销,有并发访问时要计算本地数据使用周期内的并发上限,否则可能会导致内存溢出。
综合考虑,一般IN里面的值个数超过20个以后性能基本没什么太大变化,也特别说明不要超过100,超过后可能会引起执行计划的不稳定性及增加数据库CPU及内存成本,这个需要专业DBA评估。
当我们采用select从数据库查询数据时,数据默认并不是一条一条返回给客户端的,也不是一次全部返回客户端的,而是根据客户端fetch_size参数处理,每次只返回fetch_size条记录,当客户端游标遍历到尾部时再从服务端取数据,直到最后全部 传送完成。所以如果我们要从服务端一次取大量数据时,可以加大fetch_size,这样可以减少结果数据传输的交互次数及服务器数据准备时间,提高性能。
以下是jdbc测试的代码,采用本地数据库,表缓存在数据库CACHE中,因此没有网络连接及磁盘IO开销,客户端只遍历游标,不做任何处理,这样更能体现fetch参数的影响:
String vsql ="select * from t_employee";
PreparedStatement pstmt = conn.prepareStatement(vsql,ResultSet.TYPE_FORWARD_ONLY,ResultSet.CONCUR_READ_ONLY);
pstmt.setFetchSize(1000);
ResultSet rs = pstmt.executeQuery(vsql);
int cnt = rs.getMetaData().getColumnCount();
Object o;
while (rs.next()) {
for (int i = 1; i <= cnt; i++) {
o = rs.getObject(i);
}
}
测试示例中的employee表有100000条记录,每条记录平均长度135字节
以下是测试结果,对每种fetchsize测试5次再取平均值:
| fetchsize | elapse_time(s) |
| 1 | 20.516 |
| 2 | 11.34 |
| 4 | 6.894 |
| 8 | 4.65 |
| 16 | 3.584 |
| 32 | 2.865 |
| 64 | 2.656 |
| 128 | 2.44 |
| 256 | 2.765 |
| 512 | 3.075 |
| 1024 | 2.862 |
| 2048 | 2.722 |
| 4096 | 2.681 |
| 8192 | 2.715 |
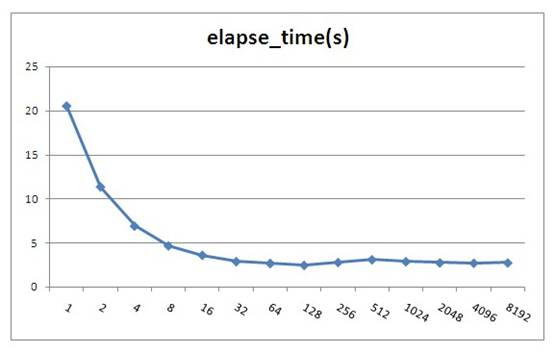
Oracle jdbc fetchsize默认值为 10,由上测试可以看出fetchsize对性能影响还是比较大的,但是当fetchsize大于100时就基本上没有影响了。fetchsize并不会存在一个最优的固定值,因为整体性能与记录集大小及硬件平台有关。根据测试 结果建议当一次性要取大量数据时这个值设置为100左右,不要小于40。注意, fetchsize不能设置太大,如果一次取出的数 据大于JVM的内存会导致内存溢出,所以建议 不要超过1000,太大了也没什么性能提高,反 而可能会增加内存溢出的危险。
注:图中fetchsize在128以后会有 一些小的波动,这并不是测试误差,而是由于resultset填充到具体对像时间不同的原因,由于resultset已经到本地内存里了,所以估计是由于CPU的L1,L2 Cache 命中率变化造成,由于变化不大,所以笔者也未深入分析原因。
iBatis的SqlMapping配置文件可以对每个SQL语句指定fetchsize大小,如下所示:
<select id="getAllProduct" resultMap="HashMap" fetchSize="1000">
select * from employee
</select>
大型数据库一般都支持存储过程,合理的利用存储过程也可以提高系统性能。如你有一个业务需要将A表的数据做一些加工然后更新到B表中,但是又不可能一条SQL完成,这时你需要如下3步操作:
a:将A表数据全部取出到客户端;
b:计算出要更新的数据;
c:将计算结果更新到B表。
如果采用存储过程你可以将整个业务逻辑封装在存储过程里,然后在客户端直接调用存储过程处理,这样可以减少网络交互的成 本。
当然,存储过程也并不是十全十美,存储过程有以下缺点:
a、不可移植性,每种数据库的内部编程语法 都不太相同,当你的系统需要兼容多种数据库时最好不要用存储过程。
b、学习成本高,DBA一般都擅长写存储过程,但并不是每个程序员都能写好存储过程,除 非你的团队有较多的开发人员熟悉写存储过程,否则后期系统维护会产生问题。
c、业务逻辑多处存在,采用存储过程后也就 意味着你的系统有一些业务逻辑不是在应用程序里处理,这种架构会增加一些系统维护和调试成本。
d、存储过程和常用应用程序语言不一样,它 支持的函数及语法有可能不能满足需求,有些逻辑就只能通过应用程序处理。
e、如果存储过程中有复杂运算的话,会增加 一些数据库服务端的处理成本,对于集中式数据库可能会导致系统可扩展性问题。
f、为了提高性能,数据库会把存储过程代码 编译成中间运行代码(类似于java的class文件) ,所以更像静态语言。当存储过程引用的对像(表、视图等等)结构改变后,存储过程需要重新编译才能生效,在24*7高并发应用场景,一般都是在线变更结构的,所以在变更的瞬间要同时编译存储过程,这可能会导致数据库瞬间压 力上升引起故障(Oracle数据库就存在这样的 问题)。
个人观点:普通业务逻辑尽量不要使用存储过程,定时性的ETL任务或报表统计函数可以根据团队资源情况采用存储过程处理。
要通过优化业务逻辑来提高性能是比较困难的,这需要程序员对所访问的数据及业务流程非常清楚。
举一个案例:
某移动公司推出优惠套参,活动对像为VIP会员并且2010年1, 2,3月平均话费20元以上的客户。
那我们的检测逻辑为:
select avg(money) as avg_money from bill where phone_no=’13988888888’ and date between ’201001’ and ’201003’;
select vip_flag from member where phone_no=’13988888888’;
if avg_money>20 and vip_flag=true then
begin
执行套参 ();
end;
如果我们修改业务逻辑为:
select avg(money) as avg_money from bill where phone_no=’13988888888’ and date between ’201001’ and ’201003’;
if avg_money>20 then
begin
select vip_flag from member where phone_no=’13988888888’;
if vip_flag=true then
begin
执行套参();
end;
end;
通过这样可以减少一些判断vip_flag的开销,平均话费20元以下的用户就不需要再检测是否VIP了。
如果程序员分析业务,VIP会员比例为1%, 平均话费20元以上的用户比例为90%,那我们改成如下:
select vip_flag from member where phone_no=’13988888888’;
if vip_flag=true then
begin
select avg(money) as avg_money from bill where phone_no=’13988888888’ and date between ’201001’ and ’201003’;
if avg_money>20 then
begin
执行套参();
end;
end;
这样就只有1%的VIP会员才会做检测平均话 费,最终大大减少了SQL的交互次数。
以上只是一个简单的示例,实际的业务总是比这复杂得多,所以一般只是高级程序员更容易做出优化的逻辑,但是我们需要有这 样一种成本优化的意识。
现在大部分Java框架都是通过jdbc从数据库取 出数据,然后装载到一个list里再处理, list里可能是业务Object,也可能是hashmap。
由于JVM内存一般都小于4G,所以不可能一次通 过sql把大量数据装载到list里。为了完成功能,很多程序员喜欢采用分页的方法处 理,如一次从数据库取1000条记录,通过多次 循环搞定,保证不会引起JVM Out of memory 问题。
以下是实现此功能的代码示例,t_employee表有10万条记录,设置分页大小为1000:
d1 = Calendar.getInstance().getTime();
vsql = "select count(*) cnt from t_employee";
pstmt = conn.prepareStatement(vsql);
ResultSet rs = pstmt.executeQuery();
Integer cnt = 0;
while (rs.next()) {
cnt = rs.getInt("cnt");
}
Integer lastid=0;
Integer pagesize=1000;
System.out.println("cnt:" + cnt);
String vsql = "select count(*) cnt from t_employee";
PreparedStatement pstmt = conn.prepareStatement (vsql);
ResultSet rs = pstmt.executeQuery();
Integer cnt = 0;
while (rs.next()) {
cnt = rs.getInt("cnt");
}
Integer lastid = 0;
Integer pagesize = 1000;
System.out.println("cnt:" + cnt);
for (int i = 0; i <= cnt / pagesize; i++) {
vsql = "select * from (select * from t_employee where id>? order by id) where rownum<=?";
pstmt = conn.prepareStatement(vsql);
pstmt.setFetchSize(1000);
pstmt.setInt(1, lastid);
pstmt.setInt(2, pagesize);
rs = pstmt.executeQuery();
int col_cnt = rs.getMetaData().getColumnCount();
Object o;
while (rs.next()) {
for (int j = 1; j <= col_cnt; j++) {
& nbsp; o = rs.getObject(j);
}
lastid = rs.getInt ("id");
}
rs.close();
pstmt.close();
}
以上代码实际执行时间为6.516秒
很多持久层框架为了尽量让程序员使用方便,封装了jdbc通过statement执行数据返回到resultset的细节,导致程序员会想采用分页的方式处理问题。实际上如果我们采用jdbc原始的resultset游标处理记录,在resultset循环读取的过程中处理记录,这样就可以一次从数据库取出所有记录。显著提高性能。
这里需要注意的是,采用resultset游标处理记录时,应该将游标的打开方式设置为FORWARD_READONLY模式(ResultSet.TYPE_FORWARD_ONLY,ResultSet.CONCUR_READ_ONLY),否则会把结果缓存在JVM里,造成JVM Out of memory问题。
代码示例:
String vsql ="select * from t_employee";
PreparedStatement pstmt = conn.prepareStatement(vsql,ResultSet.TYPE_FORWARD_ONLY,ResultSet.CONCUR_READ_ONLY);
pstmt.setFetchSize(100);
ResultSet rs = pstmt.executeQuery(vsql);
int col_cnt = rs.getMetaData().getColumnCount();
Object o;
while (rs.next()) {
for (int j = 1; j <= col_cnt; j++) {
o = rs.getObject (j);
}
}
调整后的代码实际执行时间为3.156秒
从测试结果可以看出性能提高了1倍多,如果采用分页模式数据库每次还需发生磁盘IO的话那性能可以提高更多。
iBatis等持久层框架考虑到会有这种需求,所 以也有相应的解决方案,在iBatis里我们不能 采用queryForList的方法,而应用该采用 queryWithRowHandler加回调事件的方式处理 ,如下所示:
MyRowHandler myrh=new MyRowHandler();
sqlmap.queryWithRowHandler("getAllEmployee", myrh);
class MyRowHandler implements RowHandler {
public void handleRow(Object o) {
//todo something
}
}
iBatis的queryWithRowHandler很好的封装了resultset遍历的事件处理,效果及性能与resultset遍历一样,也不会产生JVM内存溢出。
绑定变量是指SQL中对变化的值采用变量参数的形式提交,而不是在SQL中直接拼写对应的值。
非绑定变量写法:Select * from employee where id=1234567
绑定变量写法:
Select * from employee where id=?
Preparestatement.setInt(1,1234567)
Java中Preparestatement就是为处理绑定变量提供的对像,绑定变量有以下优点:
1、防止SQL注入
2、提高SQL可读性
3、提高SQL解析性能,不使用 绑定变更我们一般称为硬解析,使用绑定变量我们称为软解析。
第1和第2点很好理解,做编码的人应该都 清楚,这里不详细说明。关于第3点,到底能 提高多少性能呢,下面举一个例子说明:
假设有这个这样的一个数据库主机:
2个4核CPU
100块磁盘,每个磁盘支持IOPS为 160
业务应用的SQL如下:
select * from table where pk=?
这个SQL平均4个IO(3个索引IO+1个数据IO)
IO缓存命中率75%(索引全在内存中,数据需要访问磁盘)
SQL硬解析CPU消耗:1ms (常用经验值)
SQL软解析CPU消耗:0.02ms(常用经验值)
假设CPU每核性能是线性增长,访问内存Cache 中的IO时间忽略,要求计算系统对如上应用采 用硬解析与采用软解析支持的每秒最大并发数:
| 是否使用绑定变量 | CPU支持最大并发数 | 磁盘IO支持最大并发数 |
| 不使用 | 2*4*1000=8000 | 100*160=16000 |
| 使用 | 2*4*1000/0.02=400000 | 100*160=16000 |
从以上计算可以看出,不使用绑定变量的系统当并发达到8000时会在CPU上产生瓶颈,当使用绑定变量的系统当并行达到16000时会在磁盘IO上产生瓶颈。所以如果你的系统CPU有瓶颈时请先检查是否存在大量的硬解析操作。
使用绑定变量为何会提高SQL解析性能,这个需要从数据库SQL执行原理说明,一条SQL在Oracle数据库中的执行过程如下图所 示:
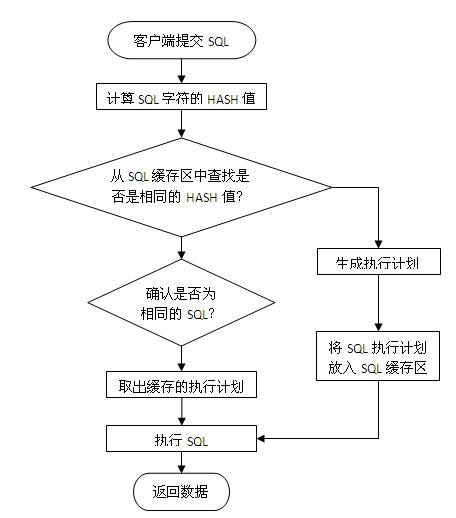
当一条SQL发送给数据库服务器后,系统首先会将SQL字符串进行hash运算,得到 hash值后再从服务器内存里的SQL缓存区中进行检索,如果有相同的SQL字符,并且确认是同一逻辑的SQL语句,则从共享池缓存中取出SQL对应的执行计划,根据执行计划读取数据并返回结果给客 户端。
如果在共享池中未发现相同的SQL则根据SQL逻辑生成一条新的执行计划并保存在SQL缓存区中,然后根据执行计划读取数据并返回结果给客户端。
为了更快的检索SQL是否在缓存区中,首先进行的是SQL字符串hash值对 比,如果未找到则认为没有缓存,如果存在再进行下一步的准确对比,所以要命中SQL缓存区应保证SQL字符是完全一致,中间有大小写或空格都会认为是不同的SQL。
如果我们不采用绑定变量,采用字符串拼接的模式生成SQL,那么每条SQL都会产生执行计划,这样会导致共享池耗尽,缓存命中率也很低。
一些不使用绑定变量的场景:
a、数据仓库应用,这种应用一般并发不高,但是每个SQL执行时间很长,SQL解析的时间相比SQL执行时间比较小, 绑定变量对性能提高不明显。数据仓库一般都是内部分析应用,所以也不太会发生SQL注入的安全问题。
b、数据分布不均匀的特殊逻辑,如产品表,记录有1亿,有一产品状态字段,上面建有索引,有审核中,审核通过,审核未通过3种状态,其中审核通过9500万,审核中1万,审核不通过499万。
要做这样一个查询:
select count(*) from product where status=?
采用绑定变量的话,那么只会有一个执行计划,如果走索引访问,那么对于审核中查询很快,对审核通过和审核不通过会很慢; 如果不走索引,那么对于审核中与审核通过和审核不通过时间基本一样;
对于这种情况应该不使用绑定变量,而直接采用字符拼接的方式生成SQL,这样可以为每个SQL生成不同的执行计划,如下所示。
select count(*) from product where status=’approved’; //不使用索引
select count(*) from product where status=’tbd’; //不使用索引
select count(*) from product where status=’auditing’;//使用索引
4.2、合理使用排序
Oracle的排序算法一直在优化,但是总体时间 复杂度约等于nLog(n)。普通OLTP系统排序操作一般都是在内存里进行的,对于数据库来 说是一种CPU的消耗,曾在PC机做过测试,单核普通CPU在1秒钟可以完成100万条记录的全内存排序操作,所以说由于现在CPU的性能增强,对于普通的几十条或上百条记录排序对系统的影响也不会很大。但是当你的记录集增加到上万 条以上时,你需要注意是否一定要这么做了,大记录集排序不仅增加了CPU开销,而且可能会由于内存不足发生硬盘排序的现象,当发生硬盘排序时性能会急剧下降,这种需求需要与DBA沟通再决定,取决于你的需求和数据,所以只有你自己最清楚,而不要被别人说 排序很慢就吓倒。
以下列出了可能会发生排序操作的SQL语法:
Order by
Group by
Distinct
Exists子查询
Not Exists子查询
In子查询
Not In子查询
Union(并集),Union All也是一 种并集操作,但是不会发生排序,如果你确认两个数据集不需要执行去除重复数据操作,那请使用Union All 代替Union。
Minus(差集)
Intersect(交集)
Create Index
Merge Join,这是一种两个表连接的内部算法,执行时会把两个表先排序好再连接,应用于两个大表连接的操作。如果你的两个表连接的条件都是等值运算,那 可以采用Hash Join来提高性能,因为 Hash Join使用Hash 运算来代替排序的操作。具体原理及设置参考SQL执行计划优化专题。
4.3、减少比较操作
我们SQL的业务逻辑经常会包含一些比较操作,如a=b,a<b之类的操作,对于这些比较操 作数据库都体现得很好,但是如果有以下操作,我们需要保持警惕:
Like模糊查询,如下所示:
a like ‘%abc%’
Like模糊查询对于数据库来说不是很擅长,特 别是你需要模糊检查的记录有上万条以上时,性能比较糟糕,这种情况一般可以采用专用Search或者采用全文索引方案来提高性能。
不能使用索引定位的大量In List,如下所示:
a in (:1,:2,:3,…,:n) ---- n>20
如果这里的a字段不能通过索引比较,那数据库会将字段与in里面的每个值都进行比较运算,如果记录数有上万以上,会明显感觉到SQL的CPU开销加大,这个情况有两种解决方式:
a、 将in列表里面的数据放入一张中间小表,采用两个表Hash Join关联的方式处理;
b、 采用str2varList方法将字段串列表转换一个临时表处 理,关于str2varList方法 可以在网上直接查询,这里不详细介绍。
以上两种解决方案都需要与中间表Hash Join的方式才能提高性能,如果采用了Nested Loop的连接方式性能会更差。
如果发现我们的系统IO没问题但是CPU 负载很高,就有可能是上面的原因,这种情况不太常见,如果遇到了最好能和DBA沟通并确认准确的原因。
4.4、大量复杂运算在客 户端处理
什么是复杂运算,一般我认为是一秒钟CPU只能做10万次以内的运算。如含小数的对数及指数运算、三角函数、3DES及BASE64数据加密算法等等。
如果有大量这类函数运算,尽量放在客户端处理,一般CPU每秒中也只能处理1万-10万次这样的函数运算,放在数据库内不利于高并发处理。
5、利用更多的资源
5.1、客户端多进程并行 访问
多进程并行访问是指在客户端创建多个进程 (线程),每个进程建立一个与数据库的连接,然后同时向数据库提交访问请求。当数据库主机资源有空闲时,我们可以采用客户端多进程并行访问的方法来提高性能。如 果数据库主机已经很忙时,采用多进程并行访问性能不会提高,反而可能会更慢。所以使用这种方式最好与DBA或系统管理员进行沟通后再决定是否采用。
标签:SQL Server
原创文章如转载,请注明:转载自郑州网建-前端开发 http://camnpr.com/本文链接:http://camnpr.com/database/115.html
相关文章
- 关系型数据库访问性能优化法则之程序员篇(2010-12-9 11:59:30)
- sql查找某个月份在开始时间和结束时间之间的记录(2010-11-24 11:50:46)
- SQL SERVER 与ACCESS、EXCEL的数据转换(2010-10-18 11:6:0)
- 【SQL Server】Sql字符串ID转换成名字(2010-9-30 16:34:22)
- 【SQL Server】SQL日期格式化函数FormatDatetime(2010-9-30 16:0:35)
- 【SQL Server】Sql实现的字符串分割自定义函数:Split(2010-9-30 15:30:56)
- 【SQL Server】清除HTML的SQL用户定义函数--不使用正则表达式(2010-9-30 15:27:27)
- 【SQL Server】在SQL中实现分割字符串功能(类似Split)(2010-9-30 15:23:48)
- 【服务器】两个服务器上的两个数据库表进行关联查询(2010-8-25 18:5:12)
- 【MYSQL】.net链接mysql数据库,操作增删改查(2010-8-25 18:3:16)