美丽说网站的SEO手段探讨 - 用户和搜索引擎区别对待
都说《美丽说》网站SEO做的很牛叉,那么今天我们来验证探讨一下,它是怎么做SEO的 - 针对搜索引擎输出网页。
看完美丽说单品页列表的HTML源码,觉得很奇怪,他们居然是用javascript脚本输出数据,然后再用javascript模板引擎渲染展示,这样搜索引擎能抓取到内容吗?
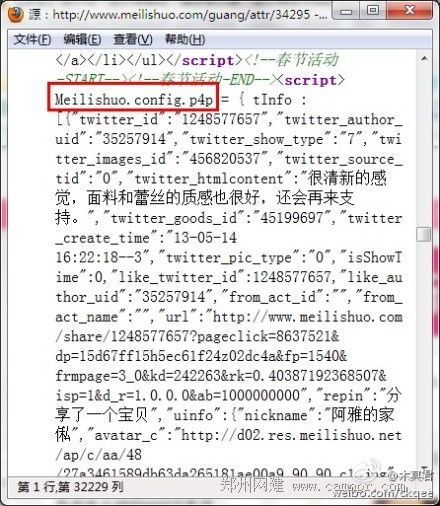
图1:Meilishuo.config.p4p用来存储条目数据
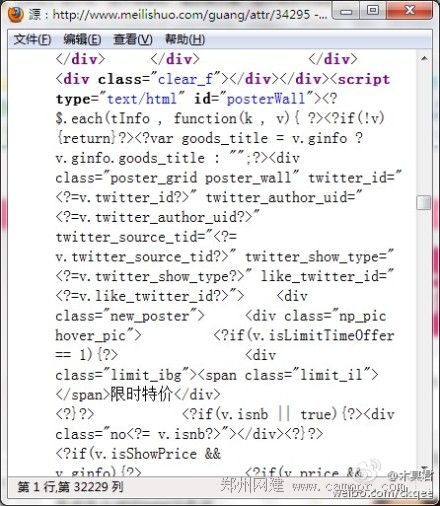
图2:使用javascript模板引擎渲染条目内容
随便找一个美丽说上“连衣裙”的网页,对应的URL=upload/2014/7/201407311404115230.jpg" alt="百度搜索“美丽说连衣裙”" width="440" height="148" >
图3:连衣裙页面在百度搜索结果中
使用百度快照功能查看该网页被百度抓取的内容(同图4),可以清楚明确的看到,缓存的网页里所有图文条目都是HTML,并未出现javascript数据和渲染代码。这就令我诧异了,难道是所谓“大站原则”,美丽说用某种特殊的协议让百度理解他们的网页内容?
以上的疑问都基于百度搜索优化一条关于SEO作弊行为的阐述:(参考文章1)
服务器端进行特殊处理:
网站自身或外链针对百度spider与用户返回不同内容。
这种SWO作弊行为叫伪装(Cloaking),通常是说在Web服务器上使用一定的手段,对搜索引擎中的巡回机器人显示出与普通阅览者不同内容的网页。
正因为这条规则,所以我并没有想美丽说是否用这个方法操作导致前面提到的现象,但我无法找到更合理的解释,所以,是时候验证一下这事了。
写一个简单的抓取程序,伪装成baiduspider去抓取该页面的内容(如图4),看完抓取来的HTML内容,前面的几个疑问解开了,美丽说的确在用典型的“伪装”手法来操作网页。在抓取过程中,发现美丽说网页对于空User-Agent的请求直接返回404页面,这应该是为了防采集设置的小门槛吧,不然没必要添加这一步去增加资源负担。
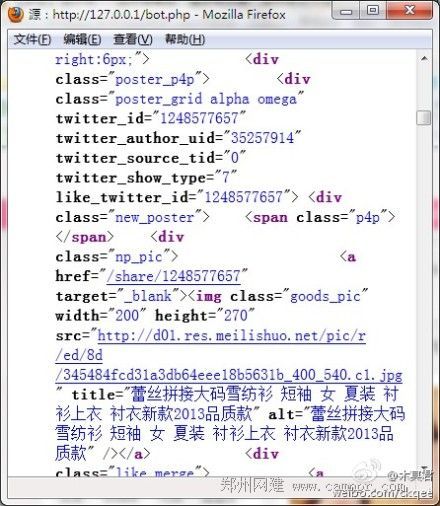
理解了操作手法,但还是不清楚其中的用意,我能想到的有:
1、防止采集。
不解:即便javascript输出数据,对于执意要采集的人也不是个难事。只是多一个门槛?代价值得吗?
2、节省资源。
美丽说网站以展示图片为主,用脚本引擎的方式,既可以让页面HTML干净,又可按需请求图片资源。
不解:javascript输出数据和HTML直接输出在后端来看,耗费一样,不是为了提高后端效率,那么,几百上千万出入的公司不至于为图片资源服务器发愁到这地步吧?况且,HTML直接输出也有按需取的办法。
3、从SEO考量而为。
不解:给搜索引擎返回纯HTML肯定是为了SEO,但疑问在于,他为啥要给用户返回不同的代码,但页面效果是完全一样的呢?
八卦一通,没啥结论,可以肯定的是美丽说这么做肯定不算SEO作弊,因为百度站长平台还有一句条例(参考文章1),着重点是“内容完全不相关”,而美丽说的做法并未违反这一原则以及欺骗用户。
存在一类作弊网站,针对百度spider以及用户返回两种不同的页面(内容完全不相关)或针对百度refer使用户跳转到其他的内容上,严格来说,这种作弊不能算在外链作弊范畴,但是是一种恶劣的作弊行为,在此一并明确一下,百度将给予此类站点更加严格的处理。
还是不理解美丽说网站这么做的真正原因,路人若有知晓的,不妨告知一下以求解惑张见识。
在整个思考过程中,"大站和搜索引擎之间有良好沟通"和“作弊手法除外”这两个固定条框局限了我的想法,导致客观不足和自由不足,此需改进。
参考文章:
1、百度站长平台《谈外链判断》 http://zhanzhang.baidu.com/wiki/160
相关文章
- 美丽说如何银行卡付款,付款使用说明书,微信支付教程,银行卡支付流程(2014-7-21 17:37:40)
- 美丽说分享宝贝(淘宝宝贝链接),为什么说“系统暂时无法响应,请稍后再试”?(2014-7-19 14:35:30)
- 美丽说首页推广技巧 让你的商品展示在首页 获取更好的展示位(2014-7-9 17:7:37)