最近的文章列表
- UTF8 与 UTF8 +BOM 区别
一个带标签,一个没有标签。
BOM是Byte Order Mark(定义字节顺序),因为在网络传输中分两种顺序:大头和小头。由于兼容性,带BOM的utf-8在一些browser中显示为乱码。
网上搜索了关于Byte Order Mark的信息:
...
在UCS 编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建- 2014/6/12 Comments:编码UTF-8UTF-8 BOM
- 总结vCard(vcf格式)通讯录格式解析
最在网络上面查找关于vcard格式的技术资料,发现中文的资料很少,只能阅读vCard MIME
Directory Profile(rfc-2426)翻译它需要花太多的时间,现在把自己的理解做下记录,
希望对大家有帮助
VCard 数据格式的标识符是VCARD
l 预定义的值类型:uri, date, date-time, float
l 新增加的值类型:binary, phone-number, utc-offset and vcard value
l 预定义的类型:SOURCE, NAME, PROFILE, BEGIN, END.
l 新增加的类型:FN, N, NICKNAME, PHOTO, BDAY, ADR, LABEL, TEL, EMAIL,
MAILER, TZ, GEO, TITLE, ROLE, LOGO, AGENT, ORG, CATEGORIES, NOTE,
PRODID, REV, SORT-STRING, SOUND, URL, UID, VERSION, CLASS, KEY
l 预定义的参数:ENCODING, VALUE, CHARSET, LANGUAGE, CONTEXT.
l 新增加的参数:TYPE
- 2014/6/10 Comments:xml转换vcfvCard
- 分享百度移动版的url编码解码示例
- 代码如下:
var decode = function(m) {
try {
m = decodeURIComponent(m);
} catch(e) {}
var s = m.split("%");
if (s.length > 1) {
s.shift();
for(var i = 0; i < s.length; i++) {
var t = s[i];
t = parseInt(t, 16); < - 2014/6/6 Comments:编码解码百度
- 页面javascript遇到乱码问题和无法转码的解决方法
昨天遇到一个棘手的问题,在老项目里加些js文件和老项目的编码格式不一致出现乱码。老页面是GB2312,链入的js文件是UTF-8,两个文件都不能转格式。
第一个想法就是将js文件中的中文转换为unicode编码。这种做法是建立在牺牲可读性的条件下的,中文全都变成密码了。
事后想想应该还有更好的方法吧,然后就去百度,方法如下:代码如下:- 2014/6/3 Comments:Javascript ErrorUTF-8
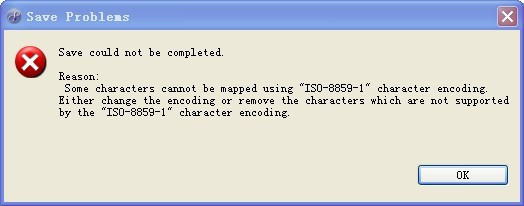
- jsp文件中文保存时提示错误:Save could not be completed. Reason using “ISO-8859-1” character encoding
在MyEclipse下编程时,保存的时候,如果出现如下图所示错误:
...
- 2013/12/7 Comments:EclipsejavaUTF-8
- C#调用C++的dll时汉字出现乱码问题
- Win32API.CommonType.USER user = new Win32API.CommonType.USER(); byte[] byt = new byte[37]; #region 给unsafe区域变量赋值 unsafe { byte[] bytUN = System.Text.Encoding.GetEncoding("GB2312").GetBytes(strUserName); for (int i = 0; i < bytUN.Length; i+
- 2011/4/8 Comments:UTF-8DLL
- GBK,GB2312,UTF8是什么?
- UTF-8:Unicode TransformationFormat-8bit,允许含BOM,但通常不含BOM。是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24为(三个字节)来编码。UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。UTF-8编码的文字可以在各国支持UTF8字符集的浏览器上显示。如,如果是UTF8编码,则在外国人的英文IE上也能显示中文,他们无需下载IE的中文语言支持包。GBK:是国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比G
- 2010/10/13 Comments:UTF-8Html
- 用Dreamweaver制作UTF-8编码的网页
- 1,在Dreamweaver中制作基于UTF-8编码的网页,首先需要进行默认设置的调整:打开编辑菜单选择首选参数(或Ctrl+U),选择新建文档分类,设置默认编码为UTF-82,建立好站点,在文件面板的站点内任意新建网页文档,并在文档窗口中打开,在页面中输入中文(主要即测试utf-8对中文的支持)3,(F12)测试该文档,页面浏览编码为utf-8,页面内容显示正常以上是对静态文档的中文显示测试,可以说明:只要定义了CODEPAGE="65001"和charset=utf-8以及保存文档编码为utf-8(注意:用DW制作的UTF-8编码网页在使用记事本编辑时,编码自动显示为utf-8),在Dreamweaver中输入的中文在浏览时均能正常显示。下面就使用>repath
- 2010/10/10 Comments:UTF-8
分门别类
 网站建设 (63)
网站建设 (63)- .Net知识问答 (137)
- 数据库 (75)
- 服务器 (92)
- 软件开发 (27)
- 性能优化_架构设计 (56)
- Javascript (447)
- Html_Css (75)
- Flash_Flex_AIR (37)
- PHP_Python (539)
- Java (0)
- CMS_SNS (15)
- 编码百科 (8)
- 应用接口 (29)
- 搜索引擎 (6)
- 地图(Maps) (13)
- 游戏(Game) (29)
- 手机开发 (84)
- 软件问题 (169)
- SEO教程 (98)
- 杂谈 (288)
- 网站百科 (4)
关注本站
一条新消息
小编推荐
- 最新评论
- 最近访客