最近的文章列表
- 分享PHP实现Javascript中的escape及unescape函数代码示例
这个类相当好用.作用么,PHP做JSON传递GBK字符,比如中文,日文,韩文神马的Unicode最合适不过了..
<?php
classcoding
{
//模仿JAVASCRIPT的ESCAPE和UNESCAPE函数的功能
function unescape($str)
{
$text=preg_replace_callback("/%u[0-9A-Za-z]{4}/",array(- 2015/6/24 Comments:函数编码解码
- php4.0.6以上中的mb_convert_encoding字符编码转换函数用法示例
本文实例讲述了php中的字符编码转换函数的用法,分享给大家供大家参考。具体实现方法如下:
一般来说,在网页程序中,尤其是涉及到数据库的读出过程中,往往最恼火的就是字符编码的问题,php4.0.6以上的版本提供了mb_convert_encoding 可以方便的转换编码。
具体如下:
- 2015/2/23 Comments:编码转换UTF-8
- 解决php中json_encode UTF-8中文乱码的更好方法
最近在接口代码当中用到过json_encode,在网上找到说json_encode编码设置为UTF-8中文就不会乱码,经验证这办法确实是有效果的,但是不知道为什么,代码在用过一段时间之后就不太管用了。以下是自己的解决json_encode的办法。有更好的方法请分享出来吧!
第一种:
这种简单的做一个代码转换,urlcode之后再返回所需数组
我代码这样就足够了。
- 2014/12/5 Comments:UTF-8中文乱码编码
- 判断网页是否是utf-8编码的php方法示例代码
//判断编码
代码如下:$encode = mb_detect_encoding($q, array('GB2312','GBK','UTF-8'));
echo $encode."<br/>";
if($encode=="GB2312")
{
$q = iconv("GBK","UTF-8",$q);
}- 2014/10/23 Comments:编码UTF-8GBKGB2312
- php判断文件编码(mb_detect_encoding)并转换为UTF-8的方法(mb_convert_encoding)
PHP转换文件编码是一个比较简单的事情,但是在开发中传递中文参数的时候,有时候不知道是什么编码,结果造成了乱码的现象。这里有个非常方便的解决办法,可以自动识别编码并转换为UTF-8。具体代码如下:
代码如下:function characet($data){
if( !empty($data) ){- 2014/8/12 Comments:编码UTF-8
- PHP对URL字符串进行base64编码和解码,更安全
如果直接使用base64_encode和base64_decode方法的话,生成的字符串可能不适用URL地址。下面的方法可以解决该问题:
URL安全的字符串编码:
代码如下:function urlsafe_b64encode($string) {
$data = base64_encode($string);
$data = str_replace(array('+','/','='),array('-','_',''),$data);
return $data;
}- 2014/7/16 Comments:编码解码乱码base64
- php解决base64编码后解码乱码的问题
在用PHP做东西的时候发现了一个问题,可以简单的归结为乱码的问题,但是这个问题不是函数本身造成的。来看看罪魁祸首是谁。
嫌疑人:base64_encode 和 base64_decode
罪行:我写了一个跳转和提示函数,接收提示信息后跳转到指定的页面,但是跳转提示时汉字乱码。
跳转模版代码如下:
代码如下:<!DOCTYPE html><html><head><meta charset="utf-8">
- 2014/7/16 Comments:编码解码乱码base64
- C#中将文件保存为utf-8无bom格式 UTF8Encoding(false)
在讲魅族M9的通讯录导出为xml格式之后, 又转换成vCard(.vcf),导出的名片后,在红米手机里无法导入,提示格式不对,最后发现,原来红米手机不支持utf8+BOM编码的名片导入。
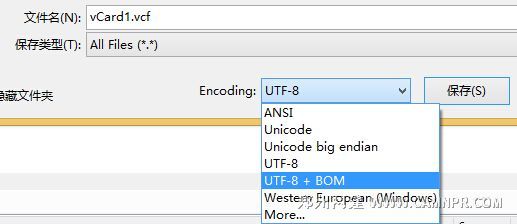
- 2014/6/12 Comments:C#UTF-8UTF-8 BOM编码
- UTF8 与 UTF8 +BOM 区别
一个带标签,一个没有标签。
BOM是Byte Order Mark(定义字节顺序),因为在网络传输中分两种顺序:大头和小头。由于兼容性,带BOM的utf-8在一些browser中显示为乱码。
网上搜索了关于Byte Order Mark的信息:
...
在UCS 编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建- 2014/6/12 Comments:编码UTF-8UTF-8 BOM
- 备忘 js unicode 编码解析关于数据转换为中文的两种方法
- 代码如下:
var str = "\\u6211\\u662Funicode\\u7F16\\u7801";
关于这样的数据转换为中文问题,常用的两种方法。
1. eval 解析代码如下: - 2014/6/12 Comments:unicode编码
分门别类
 网站建设 (63)
网站建设 (63)- .Net知识问答 (137)
- 数据库 (75)
- 服务器 (92)
- 软件开发 (27)
- 性能优化_架构设计 (56)
- Javascript (447)
- Html_Css (75)
- Flash_Flex_AIR (37)
- PHP_Python (539)
- Java (0)
- CMS_SNS (15)
- 编码百科 (8)
- 应用接口 (29)
- 搜索引擎 (6)
- 地图(Maps) (13)
- 游戏(Game) (29)
- 手机开发 (84)
- 软件问题 (169)
- SEO教程 (98)
- 杂谈 (288)
- 网站百科 (4)
关注本站
一条新消息
小编推荐
- 最新评论
- 最近访客